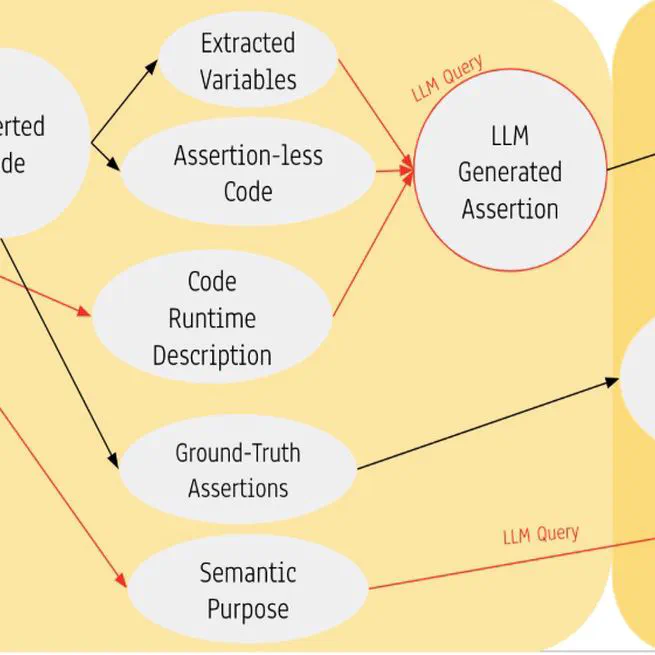
A Dataset for Benchmarking for Large Language Model-Generated Software Assertions
Software assertions play a critical role in the creation of test benches and formal property verifiction. Thus, this paper proposes a dataset of code and natural language data containing assertions in SystemVerilog and Python that can be used to train and test future collaborative coding models. Additionally, this paper provides a preliminary analysis and novel schema for the consistent generation of quality software assertions with OpenAI’s GPT-4.
May 7, 2024