A Dataset for Benchmarking for Large Language Model-Generated Software Assertions
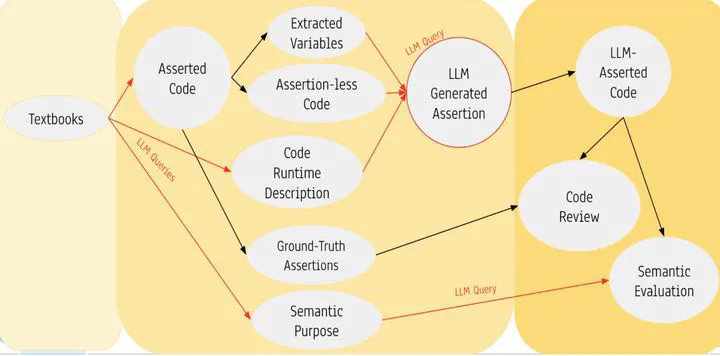 Image of Query Schema for Supervised Validation of Assertions
Image of Query Schema for Supervised Validation of AssertionsAbstract
Software assertions play a critical role in the creation of test benches and the overall verification of systems. In the case of formal property verification, complex design specifications are interpreted by industry experts and translated into System Verilog Assertions (SVA). Recent research has pointed toward large language models as a potential tool for SVA generation, however, lack of data and standardization of software assertions has resulted in mixed results amongst methods of evaluations. Thus, this paper proposes a dataset of code and natural language data containing assertions in SystemVerilog and Python that can be used to train and test future collaborative coding models. Additionally, this paper provides a preliminary analysis and novel schema for the consistent generation of quality software assertions with OpenAI’s GPT-4.
Type
Publication
A Dataset for Benchmarking for Large Language Model-Generated Software Assertions